1. 线程的实现
我们知道,线程是比进程更轻量级的调度执行单位,线程的引入,可以把一个进程的资源分配和执行调度分开,各个线程既可以共享进程资源(内存地址、文件I/O等),又可以独立调度(线程是CPU调度的基本单位)。
主流的操作系统都提供了线程实现,Java语言则提供了在不同硬件和操作系统平台下对线程操作的统一处理,每个已经执行start()且还未结束的java.lang.Thread类的实例就代表了一个线程。我们注意到Thread类与大部分的Java API有显著的差别,它的所有关键方法都是声明为Native的。在Java API中,一个Native方法往往意味着这个方法没有使用或无法使用平台无关的手段来实现(当然也可能是为了执行效率而使用Native方法,不过通常最高效率的手段也就是平台相关的手段)。正因为如此,作者把本节的标题定为“线程的实现” 而不是“Java线程的实现”。 实现线程主要有3种方式:使用内核线程实现、使用用户线程实现和使用用户线程加轻量级进程混合实现。
1.1. 使用内核线程实现
内核线程(Kernel-Levek Thread,KLT)就是直接由操作系统内核(Kernel,下称内核)支持的线程,这种线程由内核来完成线程切换,内核通过操纵调度器(Scheduler)对线程进行调度,井负责将线程的任务映射到各个处理器上。每个内核线程可以视为内核的一个分身,这样操作系统就有能力同时处理多件事情,支持多线程的内核就叫做多线程内核(Multi-Threads Kernel)。
程序一般不会直接去使用内核线程,而是去使用内核线程的一种高级接口————轻量级进程(Light Weight Process, LWP),轻量级进程就是我们通常意义上所讲的线程,由于每个轻量级进程都由一个内核线程支持,因此只有先支持内核线程,才能有轻量级进程。这种轻量级进程与内核线程之间1:1的关系称为一对一的线程模型,如下图所示:
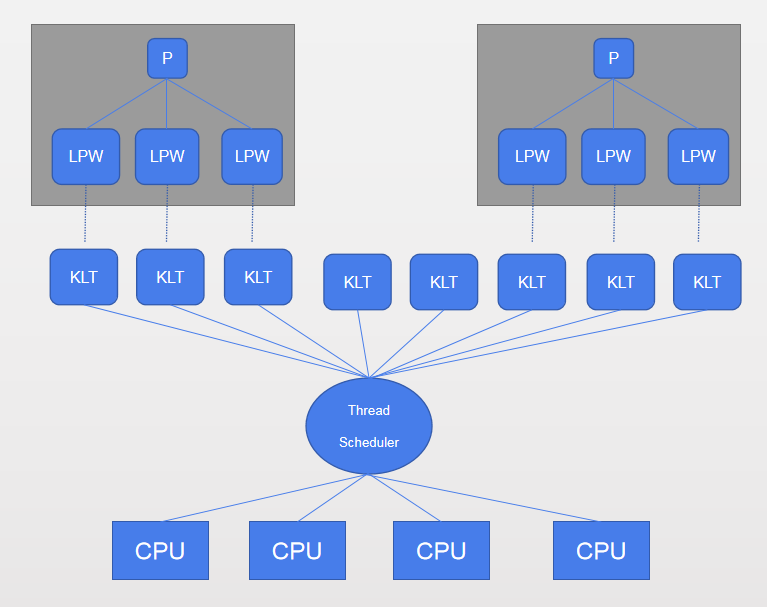
由于内核线程的支持,每个轻量级进程都成为一个独立的调度单元,即使有一个轻量级进程在系统调用中阻塞了,也不会影响整个进程继续工作,但是轻量级进程具有它的局限性:首先由于是基于内核线程实现的,所以各种线程操作,如创建、析构及同步,都需要进行系统调用。而系统调用的代价相对较高,需要在用户态(User Mode)和内核态(Kernel Mode)中来回切换。其次每个轻量级进程都需要有一个内核线程的支持,因此轻量级进程要消耗一定的内核资源(如内核线程的栈空间),因此一个系统支持轻量级进程的数量是有限的。
1.2. 使用用户线程实现
从广义上来讲,一个线程只要不是内核线程,就可以认为是用户线程(User Thread, UT),因此从这个定义上来讲,轻量级进程也属于用户线程,但轻量级进程的实现始终是建立在内核之上的,许多操作都要进行系统调用,效率会受到限制。
而狭义上的用户线程指的是完全建立在用户空间的线程库上,系统内核不能感知线程存在的实现。用户线程的建立、同步、销毁和调度完全在用户态中完成,不需要内核的帮助。如果程序实现得当,这种线程不需要切换到内核态,因此操作可以是非常快速且低消耗的,也可以支持规模更大的线程数量,部分高性能数据库中的多线程就是由用户线程实现的。这种进程与用户线程之间1:N的关系称为1对多的线程模型,如下图所示:
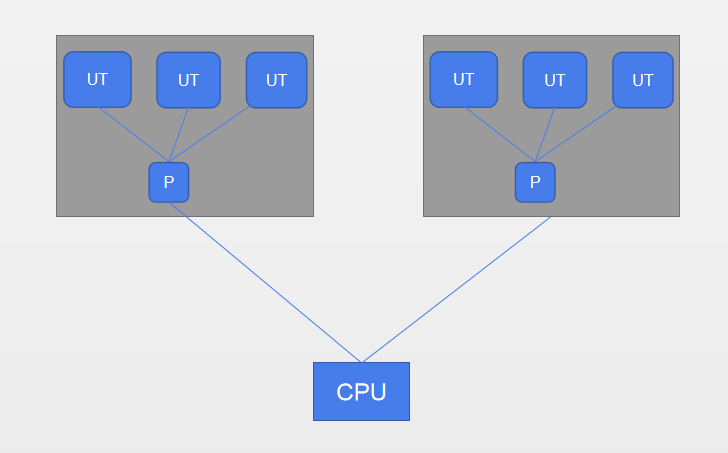
使用用户线程的优势在于并不需要系统内核支援,劣势也在于没有系统内核的支援,所有的线程操作都需要用户程序自己处理。线程的创建、切换和调度都是需要考虑的问题。而且由于操作系统只把处理器资源分配到进程,那诸如“阻塞如何处理”、“多处理器系统中如何将线程映射到其他处理器上”这类问题解决起来将会异常困难,甚至不可能完成。因为使用用户线程实现的程序一般都比较复杂,除了以前在不支持多线程的操作系统中(如DOS)的多线程程序与少数有特殊需求的程序外,现在使用用户线程的程序越来越少了,Java、Ruby等语言都曾经使用过用户线程,最终由都放弃使用它。