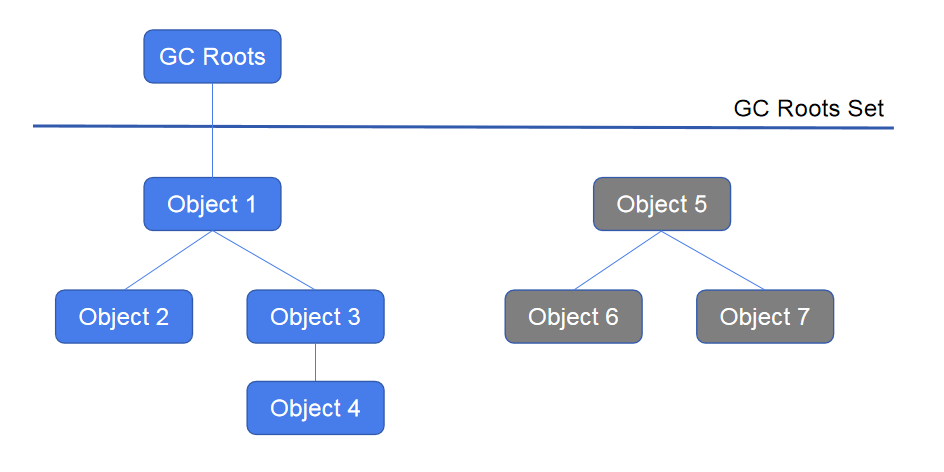
弄清楚了Full GC本意单纯就是针对老年代了之后,我们再进一步深入理解Full GC的含义。上篇文章介绍过,因为CMS主要可以分为initial mark(stop the world), concurrent mark, remark(stop the world), concurrent sweep几个阶段,其中initial mark和remark会stop the world。Full GC的次数和时间等同于老年代GC时 stop the world的次数和时间。
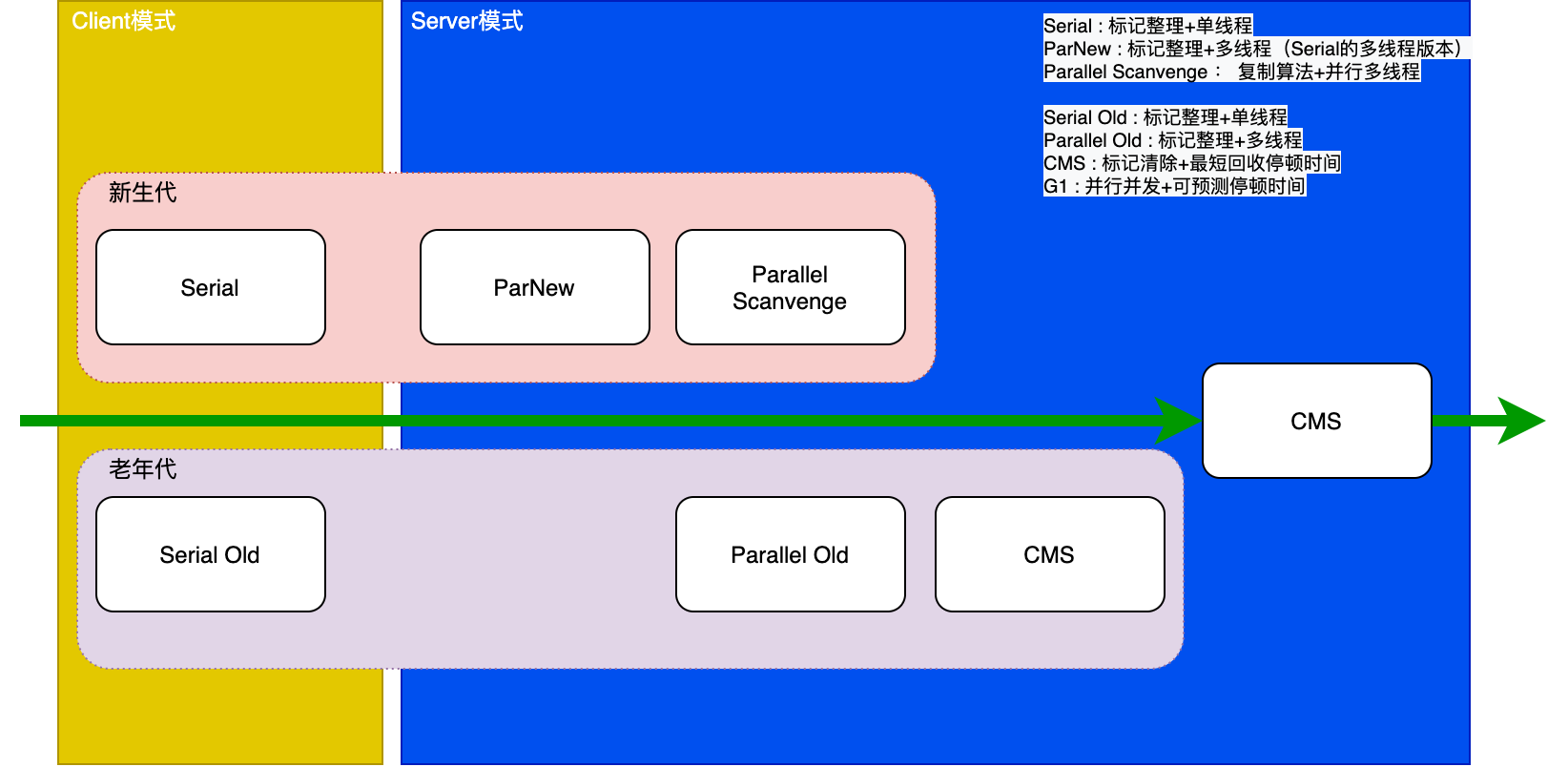
Serial 收集器是最基本、发展历史最悠久的收集器。这个收集器是一个单线程的收集器, 但它的单线程意义并不仅仅说明它只会使用一个CPU或一条收集线程去完成垃圾收集工作,更重要的是它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。 “Stop the world” 这个名字也许听起来很酷,但这项工作实际上是由虚拟机在后台自动发起和自动完成的,在用户不可见的情况下把用户正常的线程全部停掉,这对很多应用来说都是难以接受的。
从JDK1.3开始一直到JDK1.7,Hotspot虚拟机开发团队为消除或者减少工作线程因内存回收而导致停顿的努力一直在进行着,从Serial收集器到Parallel收集器,再到Concurrent Mark Sweep(CMS)乃至GC收集器的最前沿成果Garbage First(G1)收集器,我们看到一个越来越优秀、也越来越复杂的收集器出现,用户线程的停顿时间在不断缩短,但是仍然没有办法完全消除。寻找更优秀的垃圾收集器的工作仍在继续!
/** * Copies all of the elements from one list into another. After the * operation, the index of each copied element in the destination list * will be identical to its index in the source list. The destination * list must be at least as long as the source list. If it is longer, the * remaining elements in the destination list are unaffected. <p> * * This method runs in linear time. * * @param <T> the class of the objects in the lists * @param dest The destination list. * @param src The source list. * @throws IndexOutOfBoundsException if the destination list is too small * to contain the entire source List. * @throws UnsupportedOperationException if the destination list's * list-iterator does not support the <tt>set</tt> operation. */ publicstatic <T> voidcopy(List<? super T> dest, List<? extends T> src) { intsrcSize= src.size(); if (srcSize > dest.size()) thrownewIndexOutOfBoundsException("Source does not fit in dest");
if (srcSize < COPY_THRESHOLD || (src instanceof RandomAccess && dest instanceof RandomAccess)) { for (int i=0; i<srcSize; i++) dest.set(i, src.get(i)); } else { ListIterator<? super T> di=dest.listIterator(); ListIterator<? extendsT> si=src.listIterator(); for (int i=0; i<srcSize; i++) { di.next(); di.set(si.next()); } } }
/** * Created by leeeyou on 2017/4/14. */ publicclassTestGeneric2 { publicstaticvoidmain(String[] args) { List<?> data = newArrayList<>(); data.add("");//编译报错 data.add(null);//编译通过